Wat is RAID? Oorsprong, Uitleg, Bouwstenen en Configuraties
-
 Geschreven door Kees Jan Meerman
Geschreven door Kees Jan Meerman -
 Bijgewerkt op Mar 03, 2026
Bijgewerkt op Mar 03, 2026 -
 Min. Lezing 3 Min
Min. Lezing 3 Min - Deel dit
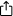
Een korte geschiedenis van RAID
Voordat moderne opslagarrays en clouddrives alledaagse hulpmiddelen werden, stonden bedrijven voor een fundamentele uitdaging: hoe konden ze groeiende hoeveelheden data op een betrouwbare en kosteneffectieve manier opslaan?
Opslagsystemen moesten gelijke tred houden met de snelle ontwikkelingen op het gebied van processors en steeds veeleisender wordende business-applicaties, maar dat bleek een hele opgave.
Halverwege de jaren tachtig vertrouwden alle serieuze datacenters nog op enkele grote, dure schijven (SLED's).
- Het vlaggenschipproduct van IBM, de 3380-behuizing, had een capaciteit van ongeveer 2,52 GB, een overdrachtssnelheid van 3 MB/s, een gemiddelde zoektijd van 16 ms en kostte tussen de 81.000 en 142.000 pond, plus een kubieke meter vloeroppervlak en een kilowatt stroom.

- Kleinere computers deden het niet veel beter: de eerste pc-harddrive, de 5,25 inch ST-506 van Shugart Technology (nu Seagate), had een capaciteit van slechts 5 MB en kostte £ 1.500 – maar liefst £ 300 per MB.

Tegelijkertijd gold de wet van Moore voor CPU's en steeds goedkopere DRAM's, waarvan de snelheid of capaciteit elke 18 tot 24 maanden verdubbelde, grotendeels ongewijzigd. Dit betekende dat transactieverwerking, SQL-databases en nieuwe client-servertoepassingen veel meer kleine willekeurige I/O-bewerkingen uitvoerden dan een enkele spindel aankon.
Onderzoekers van UC Berkeley – David Patterson, Garth Gibson en Randy Katz – kwantificeerden de kloof: de processorprestaties stegen met 40% per jaar, terwijl de mechanische latentie van een high-end harde schijf met amper 7% per jaar verbeterde.
Het resultaat was een dreigende "I/O-crisis": CPU's kwamen tot stilstand, batchvensters overschreden tijdslimieten en bedrijven werden gedwongen om kritieke tabellen over honderden SLED's te verspreiden.
Deze snelle en tijdelijke oplossing veroorzaakte nieuwe problemen.
- De kosten stegen lineair met elke extra SLED.
- De beschikbaarheid nam zelfs af, omdat meer spindels meer bronnen van storingen betekenden.
- Operators vochten een verloren strijd tegen hitte, stroomverbruik en ruimtegebrek.
Wat de industrie dringend nodig had, was doorvoer en capaciteit op mainframeniveau, maar dan tegen pc-prijzen – zonder concessies te doen aan de betrouwbaarheid.
Het waren precies deze beperkingen die de opslagonderzoekers in de jaren tachtig inspireerden.
RAID: oorsprong en definitie
Eind 1987 zetten Patterson, Gibson en Katz een klaptafel neer in een laboratorium van UC Berkeley met tien 100 MB Conner CP-3100 pc-schijven die waren aangesloten op een standaard SCSI-controller.

Zij onderzochten de volgende vraag: zou een set goedkope pc-harde schijven beter presteren dan de toonaangevende mainframe van die tijd, de IBM 3380?
Hun publicatie in SIGMOD uit 1988, "A Case for Redundant Arrays of Inexpensive Disks (RAID)", leverde de harde feiten.
| Drive (1987) | Capaciteit | Overdrachtssnelheid | Prijs/MB | Prestaties | Opslagcapaciteit |
|---|---|---|---|---|---|
| IBM 3380 AK4 | 7500 MB | ≈ 3 MB/s | 18 | 6,6 kW | 24 ft |
| Fujitsu "Super Eagle" | 600 MB | ≈ 2,5 MB/s | 20–17 | 64 | 3,4 ft |
| Conner CP-3100 | 1000 MB | ≈ 1 MB/s | 11–7 | 10 | 0,03 ft |
Vervolgens hebben zij een RAID-niveau 5-array gemodelleerd die bestaat uit 100 van deze Conner-schijven (10 data + 2 pariteit per groep).
Het resultaat:
- Ongeveer vijf keer de I/O-doorvoer, prestaties en ruimtebesparing in vergelijking met de IBM 3380
- Kosten per gigabyte met twee ordes van grootte verminderd
- Verhoogde berekende betrouwbaarheid dankzij pariteit en hot spare recovery
Met andere woorden, een array ter waarde van £ 11.000 behaalde – en vaak zelfs overtrof – de £ 100.000 SLED in alle belangrijke prestatie-indicatoren.
Deze tabel demonstreerde dat RAID niet langer een idee was, maar werkelijkheid werd, en luidde het begin van het tijdperk van de arraytechnologie in.
Wat betekent de naam "Redundant Array of Independent Disks"?
| Woord | Waarom is dit belangrijk? |
|---|---|
| Redundant | Er wordt extra informatie (volledige kopieën of pariteitscodes) opgeslagen, zodat logische data online blijft na een schijfstoring. |
| Array | Veel fysieke schijven worden gevirtualiseerd in een logische adresruimte; de manager wijst hostbloknummers toe aan schijf-/sectorlocaties, geeft opdracht tot I/O en coördineert de recovery. |
| Onafhankelijk (oorspronkelijk 'kosteneffectief') | Standaard harde schijven vallen onafhankelijk van elkaar uit en zijn veel goedkoper per GB dan een monolithische SLED. De RAID-controller compenseert dit hogere uitvalpercentage en zorgt voor een hogere MTTDL (gemiddelde tijd tot data-uitval) voor het systeem. |
| Harde schijven | Het schema is ontwikkeld voor roterende harde schijven, maar kan ook worden toegepast op SSD's en andere schijven. |
Een RAID-set is daarom een enkele virtuele harde schijf die aan de host wordt gepresenteerd en bestaat uit een groep goedkope, storingsgevoelige schijven met voldoende redundantie om de integriteit van de data te garanderen en betere prestaties te leveren.
Voordat we ingaan op specifieke RAID-niveaus, hebben we drie technische bouwstenen nodig – striping, mirroring en pariteit – evenals enkele basistermen.
- I/O (input/output): elke lees- of schrijfopdracht die door de host wordt gegeven.
- Host: de server of entiteit die verantwoordelijk is voor het verzenden van blokverzoeken via SAS, SATA, NVMe of FC.
- Blok (sector): de atomaire eenheid (512 B–4 KiB) waarin harde schijven data opslaan en RAID-algoritmen pariteit berekenen.
Met deze woordenschat kunnen we nu bekijken hoe striping de I/O versnelt, hoe mirroring onmiddellijke redundantie biedt en hoe pariteit ons in staat stelt om verloren data te herstellen met behulp van elegante XOR-wiskunde.
De drie bouwstenen van RAID: striping, mirroring en pariteit
Striping (prestaties en schaalbaarheid)
Striping is een techniek waarbij data over meerdere schijven wordt verdeeld, zodat deze parallel kunnen werken. Alle lees-/schrijfkoppen werken tegelijkertijd op de bijbehorende schijven, waardoor meer data in minder tijd kan worden verwerkt. Dit verhoogt de prestaties aanzienlijk in vergelijking met een enkele harde schijf.
Het volgende diagram laat zien hoe striping werkt in een set W-schijven. Een stripe bestaat uit N aaneengesloten blokken op een schijf; een stripe is de set uitgelijnde stripes die zich over W schijven uitstrekt (de stripe-breedte).
Stripe-grootte = stripgrootte × stripe-breedte.
De keuze van de stripe-grootte is uitsluitend een kwestie van optimalisatie van de werklast. Deze kan klein zijn (16-64 KiB) voor OLTP (online transactieverwerking) of groot (256 KiB-1 MiB) voor videostreams.
Door elke I/O-aanvraag parallel te verwerken met meerdere harde schijven, schaalbare de sequentiële bandbreedte bijna lineair met W totdat de controller of bus volledig wordt benut.
De RAID-configuratie met pure striping (d.w.z. zonder mirroring) is RAID 0, die geen redundantie biedt: als één onderdeel uitvalt, gaat de hele array verloren.
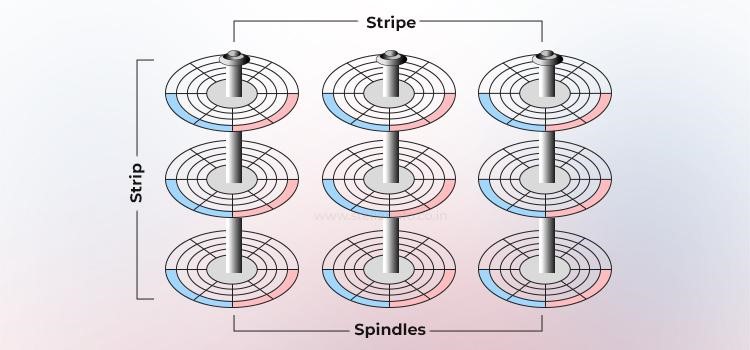
Mirroring (onmiddellijke redundantie)
Mirroring is een techniek waarbij dezelfde data op twee verschillende harde schijven wordt opgeslagen. Als één harde schijf defect raakt, blijft de data op de intacte harde schijf volledig behouden. De verantwoordelijke partij blijft de data-aanvragen van de host zonder onderbreking verwerken via het intacte onderdeel van het gespiegelde paar.
Wanneer de defecte harde schijf wordt vervangen door een nieuwe, kopieert de verantwoordelijke partij automatisch de data van de intacte harde schijf naar de nieuwe harde schijf – een proces dat transparant is voor de host.
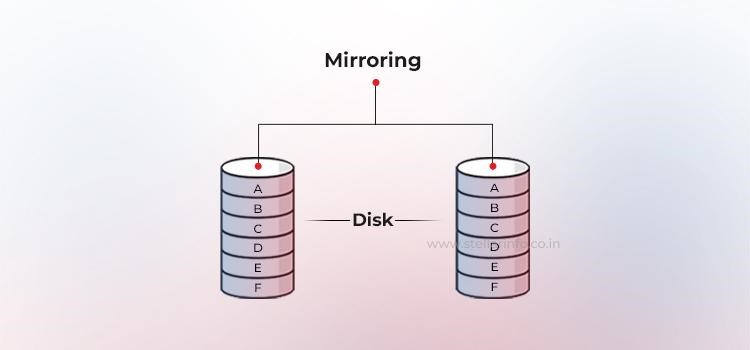
In een gespiegelde RAID-configuratie (RAID 1) wordt elke schrijfbewerking naar ten minste twee schijven verzonden. Hierdoor ontstaan dubbele datasets, ook wel submirrors genoemd. De verantwoordelijke partij kan leesbewerkingen uitvoeren vanaf de submirror die het minst bezet is.
Bedrijfsbesturingssystemen en HBA's (hostbusadapters) bieden zelfs round-robin- of geometrische leesbeleidsregels om de belasting te verdelen en de zoektijd te verkorten.
Hoewel mirroring een lichte vertraging voor schrijfopdrachten met zich meebrengt (ze moeten twee keer worden uitgevoerd) en de capaciteitsefficiëntie 50% bedraagt, wegen de voordelen op tegen de nadelen: in het geval van een schijfstoring is recovery eenvoudig – een simpele kopie van het intacte onderdeel naar een vervangende schijf.
Pariteit (wiskundig gebaseerde redundantie)
Pariteit is een methode om gestripte data te beschermen tegen hardeschijfstoringen zonder de volledige kosten van mirroring. In plaats van alle data te dupliceren, gebruiken RAID-arrays een extra harde schijf (of gedistribueerde opslagruimte) om pariteit op te slaan – een wiskundige samenvatting van de data waarmee het systeem verloren informatie kan reconstrueren.
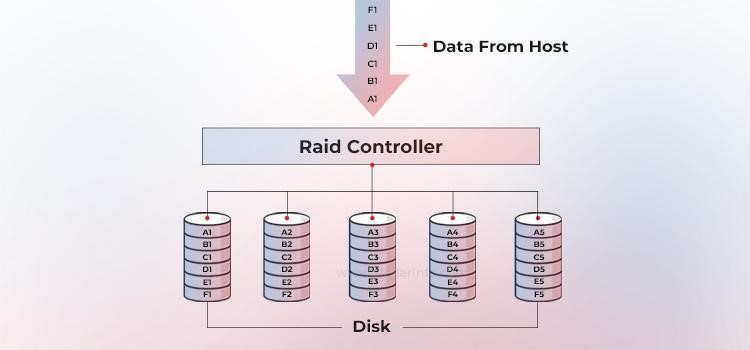
Deze pariteit wordt berekend door de RAID-controller met behulp van een bitgewijze XOR-bewerking op alle gegevensblokken in een stripe. Als een schijf defect raakt, kan het ontbrekende blok onmiddellijk worden hersteld door de resterende data te XOR-en met de opgeslagen pariteit.
Neem bijvoorbeeld drie bits: A, B en C, waarbij A de pariteit is die wordt gegenereerd uit B en C. Zo werkt XOR:
| B | C | A = B ⊕ C |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Als u A en B of C kent, kunt u altijd het derde element herstellen. Dit is het pariteitsprincipe dat RAID gebruikt om ontbrekende datablokken te herstellen.
Pariteitsinformatie kan worden opgeslagen op een speciale harde schijf (RAID 4) of worden verdeeld over alle leden (RAID 5). RAID 6 gaat nog een stap verder en voegt een tweede pariteitsblok toe, waardoor data recovery mogelijk is in het geval van twee gelijktijdige storingen. Het nadeel is een kleine hoeveelheid schrijfoverhead: elke keer dat er een update is, worden zowel de originele data als de pariteit gewijzigd, wat extra lees-, wijzigings- en schrijfcycli vereist die van invloed zijn op de prestaties.
RAID is een raamwerk – elk niveau lost een ander probleem op
De publicatie van Berkeley uit 1988 deed dus meer dan alleen een acroniem bedenken: het definieerde een raamwerk voor het schalen van opslagsystemen langs drie assen: prestaties, capaciteits efficiëntie en fouttolerantie.
- Pure striping zonder redundantie werd RAID 0.
- Door volledige duplicatie toe te voegen ontstaat RAID 1, dat beschikbaarheid voorrang geeft boven bruikbare terabytes.
- Door striping te combineren met wiskundige pariteit krijgt u RAID 5- en 6-configuraties, die wat schrijfsnelheid opofferen om het uitvallen van één of zelfs twee schijven te overleven.
Elke configuratie is gewoon een ander punt in de ruimte die is vastgelegd in het SIGMOD-document uit 1988.
Lees verder over gerelateerde onderwerpen om uw kennis over RAID te verdiepen:


Over de auteur




